

Table of Contents
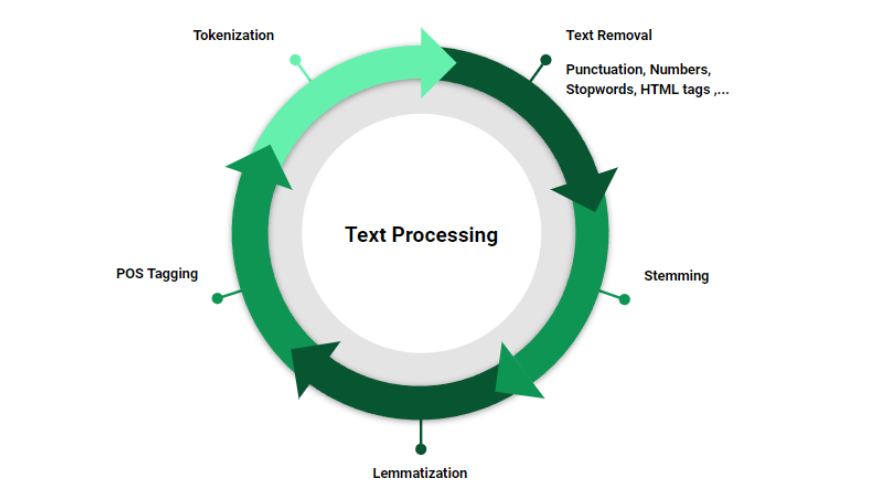
Text Processing
Text preprocessing in NLP is a crucial step in Natural Language Processing (NLP) that involves transforming raw text into a structured format, making it ready for further analysis. In NLP, handling unstructured text data can be challenging due to variations in language, syntax, and grammar. Effective text preprocessing helps in converting this data into a cleaner and more understandable format, ensuring that machine learning models can extract meaningful insights. In this article, we’ll explore the key techniques of text preprocessing in NLP using Python, covering essential steps like tokenization, stop words removal, stemming, and more.
Basic Terminology of Text preprocessing in NLP
Before diving into the text preprocessing in NLP techniques, it’s essential to understand some basic terminology used in NLP:
- Corpus: A collection of text documents, such as paragraphs, articles, or an entire book, that serves as the source for textual analysis.
- Documents: Each individual piece within a corpus, often represented as sentences, paragraphs, or even entire pages.
- Vocabulary: The set of unique words present in the entire corpus. Vocabulary size is a key metric in text preprocessing and analysis.
- Words: The smallest units of text data that form the basis of natural language. Words are essential building blocks for creating features used in machine learning models.
Having a clear understanding of these terms helps in establishing a strong foundation for various text preprocessing in NLP.
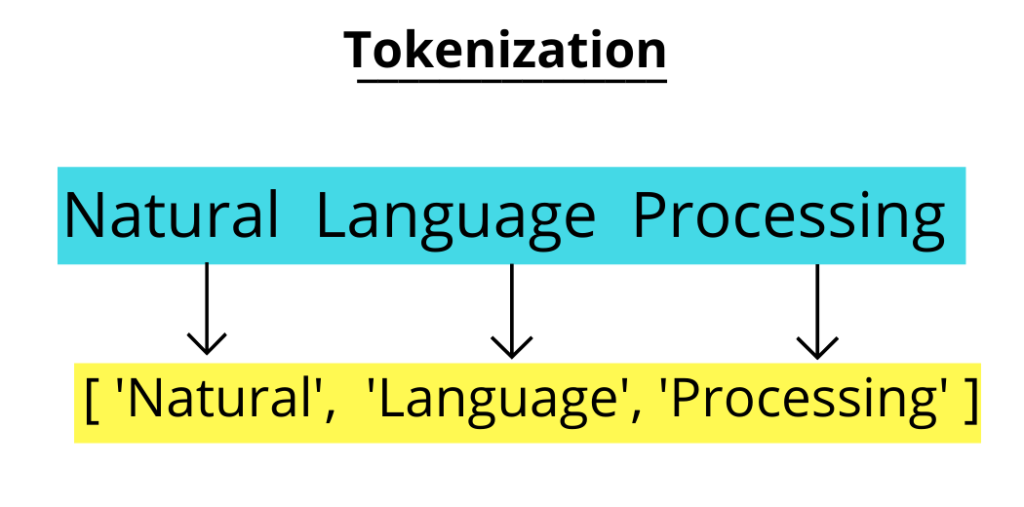
Tokenization in NLP with Python
Tokenization is the process of breaking down a larger body of text into smaller units called tokens. These tokens can be words, phrases, or even entire sentences, depending on the level of tokenization. In NLP, tokenization is a fundamental step because it allows text data to be structured in a way that machines can interpret and analyze. For example, converting a paragraph into individual sentences or splitting sentences into words are common forms of tokenization. Using Python libraries like NLTK or SpaCy, you can easily implement tokenization and prepare your text data for subsequent preprocessing steps. Below, we demonstrate the practical application of tokenization using the Natural Language Toolkit (NLTK) library.
Sentence Tokenizer (sent_tokenize): This method splits the entire text into individual sentences. It is particularly useful when you want to analyze sentence-level data.
corpus = """
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book.
"""
# Sentence Tokenizer: Splitting the paragraph into sentences
from nltk.tokenize import sent_tokenize
import nltk
nltk.download('punkt')
docs = sent_tokenize(corpus)
print("Sentence Tokenization Result:")
print(docs)Word Tokenizer (word_tokenize): A basic method to split text into words by identifying spaces and punctuation marks.
# Word Tokenizer: Splitting text into individual words
from nltk.tokenize import word_tokenize
words = word_tokenize(corpus)
print("\nWord Tokenization Result using word_tokenize:")
print(words)Word Tokenizer (wordpunct_tokenize): This tokenizer splits text based on both spaces and punctuations, making it suitable for tasks where punctuation has meaning.
# Word Tokenizer: Using wordpunct_tokenize for tokenizing based on punctuation
from nltk.tokenize import wordpunct_tokenize
words_with_punct = wordpunct_tokenize(corpus)
print("\nWord Tokenization Result using wordpunct_tokenize:")
print(words_with_punct)Treebank Word Tokenizer (TreebankWordTokenizer): A more sophisticated tokenizer that follows the Penn Treebank conventions. It is useful for handling contractions and special characters effectively.
# Word Tokenizer: Using TreebankWordTokenizer for finer tokenization
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
treebank_words = tokenizer.tokenize(corpus)
print("\nWord Tokenization Result using TreebankWordTokenizer:")
print(treebank_words)Stemming in NLP with Python
Stemming is a text normalization technique that reduces words to their base or root form. This process is useful in scenarios where different variations of a word need to be treated as the same entity. Each stemming method in Python uses a unique set of rules, resulting in different outcomes. Below, we explore three popular stemmers using various examples to highlight their differences.
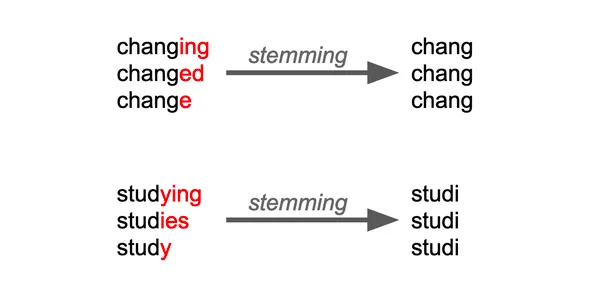
Porter Stemmer: The Porter Stemmer applies a sequence of standard rules to iteratively reduce words to their root form. Example: running --> run, happiness --> happi, activation --> activ
# Sample list of words for demonstrating different stemming techniques
words = ["running", "runner", "ran", "happier", "happiness", "generous", "generously", "activation", "active", "activities"]
# Porter Stemmer: Applying a standard set of rules to shorten words to their root forms
from nltk.stem import PorterStemmer
porter_stemmer = PorterStemmer()
print("Porter Stemmer Results:")
for word in words:
print(f"{word} --> {porter_stemmer.stem(word)}")Regular Expression Stemmer: This stemmer uses user-defined patterns to remove or modify suffixes. It’s useful when you need to tailor the stemming process for specific words or suffix patterns. Example: running --> runn, generously --> generous, activation --> activat
# Regular Expression Stemmer: Customizing rules based on patterns to remove specific suffixes
from nltk.stem import RegexpStemmer
reg_stemmer = RegexpStemmer('ing$|er$|ness$|ly$', min=5) # Custom rule to remove specific endings
print("\nRegular Expression Stemmer Results:")
for word in words:
print(f"{word} --> {reg_stemmer.stem(word)}")Snowball Stemmer: This stemmer is more sophisticated and handles multiple languages, making it ideal for applications needing more accurate results. Example: runner --> runner, happier --> happier, activities --> activ
# Snowball Stemmer: A more comprehensive stemmer supporting multiple languages
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer('english')
print("\nSnowball Stemmer Results:")
for word in words:
print(f"{word} --> {snowball_stemmer.stem(word)}")Lemmatization in NLP with Python
Lemmatization is a text normalization technique similar to stemming, but it focuses on reducing words to their lemma or root form while considering the context and part of speech (POS). Unlike stemming, which may produce non-standard words, lemmatization ensures that the transformed word is a valid dictionary word. This process is crucial for applications like Q&A systems, chatbots, and text summarization, where preserving the meaning of words is essential.

Let’s explore how to implement lemmatization in Python using the WordNetLemmatizer from the NLTK library:
# Importing the WordNetLemmatizer from NLTK
from nltk.stem import WordNetLemmatizer
# Initializing the lemmatizer
lemmatizer = WordNetLemmatizer()
# Lemmatizing a single word with the 'verb' POS tag
print("Single word lemmatization with POS as Verb:")
print(f"swimming --> {lemmatizer.lemmatize('swimming', pos='v')}")
# List of words for lemmatization demonstration
words = ["driving", "drove", "driven", "thinking", "thought", "jumps", "jumping", "happiest", "better", "running"]
# Applying lemmatization on the list of words with the 'verb' POS tag
print("\nLemmatization Results for a List of Words:")
for word in words:
print(f"{word} --> {lemmatizer.lemmatize(word, pos='v')}")
Stopwords in NLP with Python
Stopwords are common words in any language that do not contribute significant meaning to a sentence. Examples include “is,” “and,” “the,” “of,” and many others. These words often act as fillers and are usually filtered out during text preprocessing because they do not provide valuable insights for text analysis. Removing stopwords helps reduce the size of the text data and enhances the performance of machine learning models. In this section, we will demonstrate how to remove stopwords using the NLTK library in Python.
# Importing necessary libraries from NLTK
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Sample text for stopwords removal demonstration
sample_text = "This is a simple example to show how stopwords are removed from a sentence."
# Setting up the list of English stopwords
stop_words = set(stopwords.words('english'))
# Tokenizing the sample text into individual words
words = word_tokenize(sample_text)
# Filtering out stopwords from the tokenized words
filtered_words = [word for word in words if word.lower() not in stop_words]
print("Original Sentence:")
print(sample_text)
print("\nFiltered Sentence (Without Stopwords):")
print(" ".join(filtered_words))
Part of Speech (POS) Tagging in NLP with Python
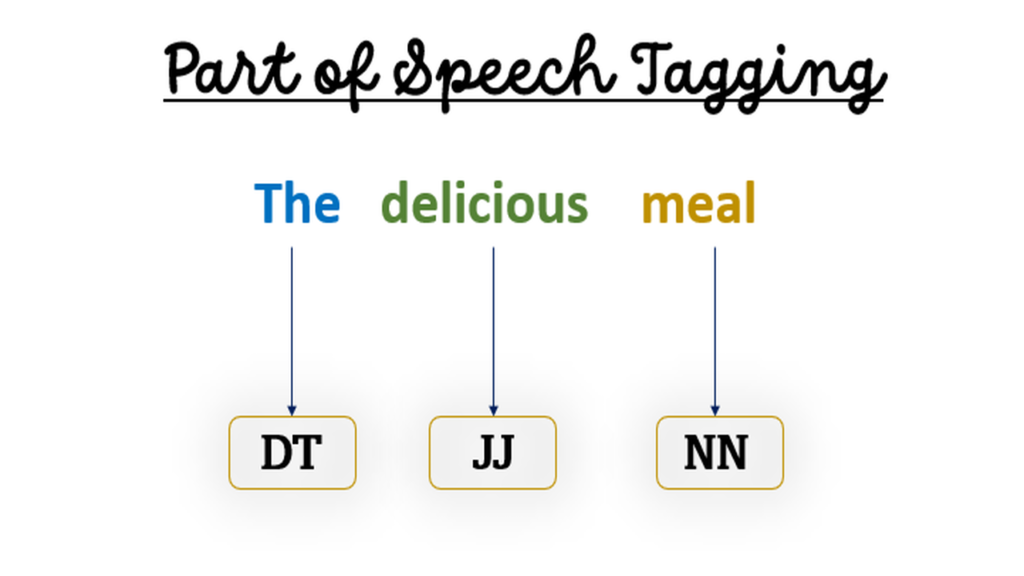
Part of Speech (POS) tagging is the process of assigning grammatical tags, such as noun, verb, adjective, or adverb, to each word in a sentence. POS tagging is crucial for understanding the syntactic structure of a sentence, which can help in various downstream tasks like named entity recognition, dependency parsing, and sentiment analysis. By knowing the role each word plays in a sentence, NLP models can extract deeper insights from the text. In this section, we will use the nltk library in Python to perform POS tagging.
# Importing necessary modules from NLTK
import nltk
from nltk.tokenize import word_tokenize
from nltk import pos_tag
# Sample text for POS tagging demonstration
sample_text = "The quick brown fox jumps over the lazy dog."
# Tokenizing the text into words
words = word_tokenize(sample_text)
# Applying POS tagging to the tokenized words
pos_tags = pos_tag(words)
print("Words with POS Tags:")
print(pos_tags)Named Entity Recognition (NER) in NLP with Python

Named Entity Recognition (NER) is a crucial technique in NLP that involves identifying and classifying entities such as people, organizations, locations, dates, and more within a text. This is highly useful for extracting meaningful information from unstructured data, making it easier to identify key elements like names, places, or monetary values. NER is widely used in tasks such as information extraction, question answering, and text summarization. In this section, we will implement Named Entity Recognition using the nltk library in Python.
# Importing necessary modules from NLTK
import nltk
from nltk import word_tokenize, pos_tag, ne_chunk
# Sample text for NER demonstration
sample_text = "Apple Inc. was founded by Steve Jobs in Cupertino, California on April 1, 1976."
# Tokenizing the text into words
words = word_tokenize(sample_text)
# Applying POS tagging to the tokenized words
pos_tags = pos_tag(words)
# Performing Named Entity Recognition
named_entities = ne_chunk(pos_tags)
print("Named Entities:")
print(named_entities)Conclusion
Text preprocessing in NLP with Python is a fundamental step in preparing raw text data for analysis. By using techniques like tokenization, stemming, lemmatization, stopword removal, POS tagging, and named entity recognition, we can efficiently transform unstructured text into a format that is ready for machine learning models. Each of these methods is crucial for refining text data and extracting meaningful insights. Whether you’re building chatbots, performing text classification, or conducting sentiment analysis, mastering text preprocessing in NLP with Python is essential for improving the performance and accuracy of your NLP applications.
FAQs
What is text preprocessing in NLP with Python?
Text preprocessing in NLP with Python involves transforming raw text data into a structured format, which makes it easier for machine learning models to process. It includes various techniques like tokenization, stemming, lemmatization, stopword removal, and POS tagging to clean and prepare the text for analysis.
Why is text preprocessing in NLP with Python important for NLP tasks?
Text preprocessing in NLP with Python is crucial because it removes noise and irrelevant data from the text, allowing NLP models to focus on meaningful content. This step helps improve the accuracy of tasks such as sentiment analysis, text classification, and named entity recognition.
What is the difference between stemming and lemmatization in text preprocessing in NLP?
In text preprocessing, stemming reduces words to their root form by applying rules, which can sometimes result in non-dictionary words (e.g., “running” becomes “run”). Lemmatization, on the other hand, considers the context and part of speech to return valid words (e.g., “better” becomes “good”).
How does stopword removal enhance text preprocessing in NLP with Python?
Stopword removal is an essential part of text preprocessing in NLP with Python because it filters out common words like “is,” “and,” or “the,” which do not add significant meaning. Removing these words helps focus on the more important terms in the text, making the analysis more efficient.

