

Table of Contents
Text representation techniques in NLP (Natural Language Processing) play a crucial role in converting raw text into numerical formats that machines can process. These techniques enable NLP models to analyze, classify, and interpret text effectively. From fundamental methods like One-Hot Encoding and Bag of Words to more advanced approaches such as Word Embeddings and Word2Vec, each technique has its unique benefits and applications. In this post, we will explore nine essential text representation techniques in NLP, discussing their advantages, disadvantages, and practical usage in various NLP tasks, including sentiment analysis and text classification.
One-Hot Encoding: Text representation techniques in NLP
One-Hot Encoding is one of the simplest and most popular text representation techniques in NLP. It converts words or characters into binary vectors, where each unique word is assigned a distinct vector with all elements set to 0 except for one element, which is set to 1. This technique is commonly used when dealing with categorical data or when preparing text data for machine learning algorithms.
Though effective for smaller vocabularies, One-Hot Encoding has its limitations, especially for large datasets, as it can lead to high-dimensional vectors with sparse data. Let’s take a look at advantages and disadvantages of One-Hot Encoding:
| Advantages | Disadvantages |
| Simple to implement and easy to understand. | Inefficient for large vocabularies, leading to high-dimensional vectors. |
| Suitable for small datasets. | No understanding of word semantics or context. |
| Works well with algorithms like Naive Bayes. | Each word is treated independently, ignoring relationships between words. |
| Can be used for both words and characters. | Results in sparse data matrices, affecting model performance. |
One-Hot Encoding in Python
# Importing necessary libraries
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Sample data for One-Hot Encoding
words = np.array([['apple'], ['orange'], ['banana'], ['apple']])
# Initializing the OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
# Applying One-Hot Encoding
one_hot_encoded = encoder.fit_transform(words)
print("Original Words:")
print(words)
print("\nOne-Hot Encoded Vectors:")
print(one_hot_encoded)Bag of Words in NLP
Bag of Words (BoW) is a fundamental text representation technique in NLP that converts text data into numerical features based on word occurrences. In this method, the text is treated as a collection (or “bag”) of words, disregarding grammar and word order. Each unique word in the corpus becomes a feature, and its value in a sentence or document corresponds to the number of times it appears.
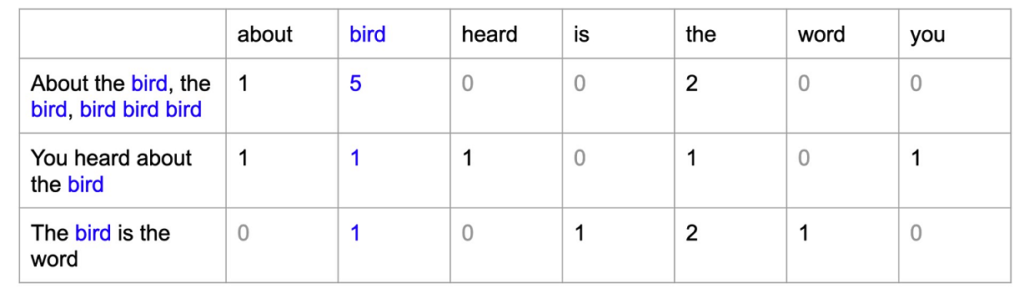
This technique is often used in text classification tasks, such as spam detection or sentiment analysis, where word frequencies can provide valuable insights. Let’s take a look at advantages and disadvantages of BOW:
| Advantages | Disadvantages |
| Simple to implement and interpret. | Ignores word order, context, and semantics. |
| Works well for small text datasets. | Can lead to high-dimensional, sparse matrices. |
| Suitable for machine learning models like Naive Bayes and Logistic Regression. | Fails to capture relationships between words. |
| Provides a straightforward way to represent text numerically. | More relevant words may not be given priority based on their frequency alone. |
Bag of Words in Python
# Importing necessary libraries
from sklearn.feature_extraction.text import CountVectorizer
# Sample data for Bag of Words
corpus = [
"Apple and orange are fruits",
"I love eating apple",
"Orange juice is refreshing"
]
# Initializing the CountVectorizer
vectorizer = CountVectorizer()
# Applying Bag of Words encoding
X = vectorizer.fit_transform(corpus)
print("Feature Names (Vocabulary):")
print(vectorizer.get_feature_names_out())
print("\nBag of Words Encoded Matrix:")
print(X.toarray())N-Grams in NLP
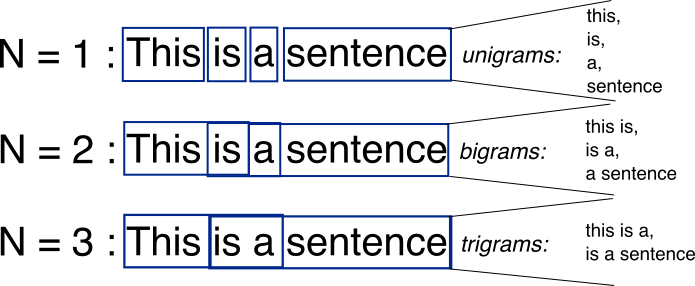
N-Grams is an advanced text representation technique in NLP that captures sequences of n consecutive words or tokens from a given text. Unlike Bag of Words, which treats each word independently, N-Grams retains some level of word order and context. An N-Gram of size 1 is called a unigram, size 2 is a bigram, and size 3 is a trigram. N-Grams are particularly useful for applications where the relationship between adjacent words plays a key role, such as language modeling and text generation. Let’s take a look at advantages and disadvantages of N-Grams:
| Advantages | Disadvantages |
| Captures limited word order and context. | Increasing N leads to more features and higher dimensionality. |
| Useful for tasks like language modeling and text generation. | More complex to implement compared to unigrams or BoW. |
| Improves performance in NLP tasks requiring sequence information. | Large N-Grams may result in sparse matrices. |
| Helps identify common phrases and collocations. | May suffer from overfitting on small datasets. |
N-Grams in Python
# Importing necessary libraries
from sklearn.feature_extraction.text import CountVectorizer
# Sample data for N-Grams demonstration
corpus = [
"I love natural language processing",
"NLP models rely on text representation techniques",
"Text representation is crucial in NLP"
]
# Initializing the CountVectorizer to generate bigrams (N=2)
vectorizer = CountVectorizer(ngram_range=(2, 2))
# Applying N-Gram encoding
X = vectorizer.fit_transform(corpus)
print("Bigram Feature Names (Vocabulary):")
print(vectorizer.get_feature_names_out())
print("\nN-Grams Encoded Matrix:")
print(X.toarray())TF-IDF in NLP
Term Frequency-Inverse Document Frequency (TF-IDF) is a widely used text representation technique in NLP that measures the importance of a word in relation to a document within a larger corpus. TF-IDF is designed to highlight words that are frequent in a specific document but not common across all documents in the corpus, making it more insightful than simple frequency-based approaches like Bag of Words. This technique is particularly useful for tasks such as document classification, information retrieval, and search engines. Let’s take a look at advantages and disadvantages of TF-IDF:
| Advantages | Disadvantages |
| Captures the importance of words within a specific context. | Computationally intensive for large datasets. |
| Reduces the influence of commonly occurring words like stopwords. | Fails to capture the sequence or order of words. |
| Works well for feature extraction in text classification. | Requires a predefined corpus to calculate IDF values. |
| Enhances the performance of search engines and information retrieval systems. | Sensitive to vocabulary changes in dynamic corpora. |
TF-IDF in Python
# Importing necessary libraries
from sklearn.feature_extraction.text import TfidfVectorizer
# Sample data for TF-IDF demonstration
corpus = [
"I enjoy learning NLP techniques",
"Text representation techniques help build NLP models",
"TF-IDF is an important text representation method"
]
# Initializing the TfidfVectorizer
vectorizer = TfidfVectorizer()
# Applying TF-IDF encoding
X = vectorizer.fit_transform(corpus)
print("TF-IDF Feature Names (Vocabulary):")
print(vectorizer.get_feature_names_out())
print("\nTF-IDF Encoded Matrix:")
print(X.toarray())Want to dive deeper into text preprocessing? Click here to learn essential techniques for text preprocessing in NLP with Python.
Word Embeddings in NLP
Word Embeddings are advanced text representation techniques in NLP that map words into continuous vector spaces, capturing semantic relationships and contextual similarities between words. Unlike techniques such as Bag of Words or TF-IDF, which represent words as isolated units, word embeddings enable words with similar meanings to have similar representations. This is achieved by positioning similar words closer to each other in the vector space, providing a powerful way to model language.
Understanding the Landscape of Text Representation Techniques
In the journey of Text Representation Techniques in NLP, various methods are aligned based on complexity and contextual understanding. Below is a breakdown of where different techniques stand:
- One-Hot Encoding and Bag of Words: These are basic techniques, representing words as sparse vectors without capturing semantic meaning or context.
- N-Grams and TF-IDF: These techniques improve on the basics by incorporating frequency and limited context (like consecutive words in N-Grams) but still lack true semantic understanding.
- Word Embeddings: Techniques such as Word2Vec, GloVe, and FastText take a step further by encoding semantic and syntactic similarities, allowing words with similar meanings to have closer embeddings in the vector space.
Word embeddings revolutionized NLP by providing dense vector representations that capture the context and meaning of words, making them ideal for deep learning applications.
Word2Vec: CBOW and Skip-Gram Models
Word2Vec is one of the most popular word embedding techniques, developed by Google. It provides two primary architectures:
- Continuous Bag of Words (CBOW): In this approach, the model predicts the target word based on its surrounding context words. For instance, given the words “I enjoy … in NLP,” CBOW would predict the word “learning.” This model works well for frequent words and tends to be faster.
- Skip-Gram: In contrast, Skip-Gram takes a target word and predicts its surrounding context words. For example, given the word “NLP,” Skip-Gram would predict “learning” and “techniques” in the sentence “I enjoy learning NLP techniques.” This model works better with rare words and captures a wider context.
Both CBOW and Skip-Gram allow the model to learn word relationships based on co-occurrence, resulting in embeddings that reflect word similarities and meanings.
Word2Vec in Python using Gensim
Below is a Python code example demonstrating how to implement Word2Vec using the Gensim library. We’ll use the Skip-Gram model to train word embeddings on a sample corpus.
# Importing necessary libraries
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample corpus
corpus = [
"Natural language processing enables computers to understand human language",
"Word embeddings represent words in a continuous vector space",
"CBOW and Skip-Gram are models used in Word2Vec"
]
# Tokenizing the sentences into words
tokenized_corpus = [word_tokenize(sentence.lower()) for sentence in corpus]
# Initializing and training the Word2Vec model using Skip-Gram
model = Word2Vec(sentences=tokenized_corpus, vector_size=100, window=5, min_count=1, sg=1) # sg=1 sets Skip-Gram model
# Checking the vector for a word
print("Vector representation for 'language':")
print(model.wv['language'])
# Finding similar words to a given word
print("\nWords similar to 'language':")
print(model.wv.most_similar('language'))Conclusion
Understanding text representation techniques in NLP is fundamental to creating effective machine learning models that can process and interpret text data. This comprehensive guide covered essential methods, from foundational techniques like One-Hot Encoding and Bag of Words to more advanced approaches like TF-IDF, N-Grams, and Word Embeddings. Each method plays a unique role, whether it’s for basic text analysis or for capturing complex semantic relationships between words. With these techniques, NLP practitioners can transform unstructured text data into structured numerical forms, making it ready for tasks like classification, sentiment analysis, and information retrieval. By mastering these text representation techniques, you can significantly enhance the performance and accuracy of your NLP models.
FAQs
What are text representation techniques in NLP?
Text representation techniques in NLP are methods used to convert text data into numerical formats that can be processed by machine learning models. Techniques like One-Hot Encoding, Bag of Words, and Word Embeddings help structure text data for analysis, classification, and sentiment detection.
Why is TF-IDF preferred over simpler methods for text representation techniques in NLP?
TF-IDF is preferred because it considers the importance of words in relation to a document and the entire corpus. Unlike Bag of Words, it downplays commonly occurring words, giving more relevance to unique terms, which makes it a more insightful text representation technique in NLP.
What is the difference between CBOW and Skip-Gram in Word2Vec?
In Word2Vec, CBOW predicts a target word based on its context words, while Skip-Gram predicts context words given a target word. Both are effective text representation techniques in NLP, with CBOW being faster and better for frequent words, and Skip-Gram performing well with rare words and broader contexts.
What are Word Embeddings, and why are they useful in text representation techniques in NLP?
Word Embeddings map words into continuous vector spaces, capturing semantic relationships and context. They are useful because they provide meaningful representations, enabling models to understand the similarity and context between words, which simpler techniques cannot achieve.

